fim initFim
File Integrity Manager 1.2.3

* New Icon proposed by Raiden
Etienne Vrignaud
What is Fim
With Fim you can:
Check the integrity of files that can be large and binary,
therefore not comparable (.doc, .jpg, .png, .mp3, .mp4, …)Know quickly the list files that would have been
renamed, moved, deleted or corrupted.
This can happen accidentallyKeep a log of changes done on these files and display later a detailed log of these changes
Search duplicate files and possibly to delete them then
More details in the use cases that follow…
Why I wrote Fim
A tool like Git is able to manage large binary files
But with Git the local workspace occupies at least double the space because there is all the content of the repository in the .git
And with Git you cannot permanently delete a file.
It will always exist in the Git historyMoreover all the contents of the modified files are retained.
which takes a huge space with the timeSome tools only work on specific file systems (Example: btrfs-scrub)
The goal was to have a tool that can quickly show the status of the local workspace
How it works
Fim creates the .fim directory in the workspace root. It is its repository.
Inside it stores an index of files contained in the workspace.
The index contains for each file:
— Name and size
— Attributes (dates, permissions)
— 3 small blocks hash
— 3 medium blocks hash
— Complete hash of the file
The index is called the State and the hash are done using SHA-512
A new State is created at each commit
The data of the files are not retained. One can thus put Fim in the category of the UVCS (UnVersioned System Control)
Fim workflow
1/ Create the repository Fim
2/ Work on the files, modify
...
3/ Know the state of the workspace
fim st # 'status' command4/ Commit to save the current state
fim ci -m "My commit comment"5/ Display the history
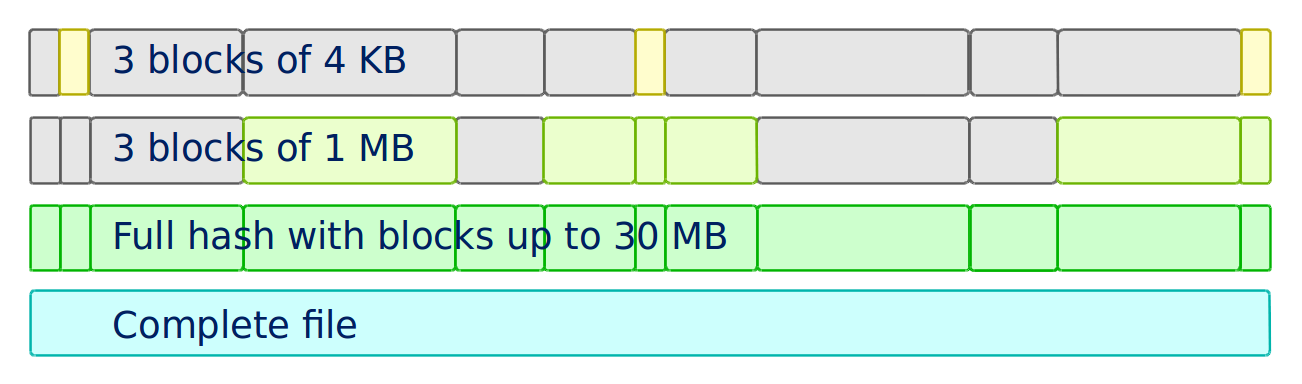
fim logSeveral hash modes
To get a faster status, Fim is able to hash only 3 blocks of the file
at the beginning, middle and end.
You can use the options:
-f: Fast mode. Hash 3 blocks of 1 MB-s: Super-fast mode. Hash 3 blocks of 4 KB
fim st -ffim st -sWith the -n option (no hash) Fim just check the file names and the attributes
fim st -n
mkdir test1
$ cd test1
$ for i in 01 02 03 04 05 06 07 08 09 10 ;
do echo "New File $i" > file${i} ; done
$ fim init -m "First State"
# Modifications
$ fim st
$ fim ci -m "My modifications"
$ fim logVarious use cases
Case 1 - Workspace management
Case 2 - Detect and remove duplicates inside a workspace
Case 3 - Duplicate files in another workspace
Case 4 - Backup integrity
Case 1 - Workspace management
Manage directories filled with binaries.
For example: photos, music or moviesKnow the state of a workspace in which we work episodically
Follow the developments over time
fim stChanges made
fim ci -m "My commit comment"
Fim does not backup the file contents.
It is recommended to use a backup software
Case 1 - Super-fast commit
The super-fast mode during a commit allows you to check the current status in super-fast mode
so that commit is faster.
The modified files are then hashed again in full mode
fim ci -s -y -m "Commit very quickly using super-fast commit"
Case 1 - Run the Fim commands from a sub-directory
Some commands are faster when they are executed from a sub-directory, because they have less files to address:
st(status): Know the status of the sub-directoryci(commit): Commit changesfdup(find-duplicates): Find duplicate filesrdup(remove-duplicates): Delete duplicate filesrfa(reset-file-attrs): Reset the files attributes
All other commands are working, but not quicker
case 1 - Ignore files or directories
You can add a .fimignore file at all the repository levels,
and also globally in the user home directory
Each line of the file contains the name of a file or directory to ignore.
You can also use the following expressions:
An asterisk to ignore several (Example:
*.mp3)**/at the beginning of the line. The remaining will be ignored in all sub directories. For example, to ignore all the mp3 even those who are in sub directories:**/*.mp3
Case 1 - Ignore some modifications
Limit the display with -i to ignore the changes on the:
attrs: File attributesdates: Modification and creation datesrenamed: Renamed files
fim st -i attrs,dates,renamedTo ignore all kinds, indicate all
fim st -i allCase 1 - Permissions management
It is important to ensure that the files keep their permissions.
Fim backup and is able to restore.
It stores for each file the following information:
You can restore the permissions using the rfa (reset-file-attrs) command:
fim rfaCase 2 - Detect duplicates inside a workspace
Fim is able to display the duplicates contained in a workspace using the command fdup (find-duplicates):
fim fdupIf the current state is already committed, you can skip the workspace scan phase by using the -l option:
fim fdup -l
Case 2 - Remove duplicates inside a workspace
It is possible to remove duplicate files.
• Either in interactive:
fim rdup• Or in automatic by keeping the first file in the duplicate set:
fim rdup -yIn both cases, it is possible to use the current state as with fdup by adding the -l option:
fim rdup -lCase 3 - Duplicate files in another workspace
Fim can delete duplicate files contained in another workspace.
For example an old backup out of sync where you want to keep only the files that you don’t have.
It removes locally all the files already contained in the master workspace.
For example, with backup which is a copy of the repository named source:
cd backup
$ fim rdup -M ../sourceWhen the workspace to clean is remote, you can just copy the .fim in an empty directory
and specify it as parameter of the -m option of the rdup command
Case 4 - Backup integrity
Fim allows you to check the integrity of files stored on any kind of file system. In particular the offline backups.
To do so, add to the backup the corresponding Fim (.fim) repository
Then it will be possible to check with Fim the integrity of the data in the backup
For example, in the case of a DVD that contains a backup and the Fim repository, you can go to the root and get the status:
fim stCase 4 - Hardware corruption detection

Fim diagnose an hardware corruption if the content of the file has changed whereas the creation / modification dates have not been modified
It uses the dcor command (detect-corruption):
fim dcor
rfacommand
Other Commands
dign(display-ignored):
Displays the files or directories ignored in the last Staterbk(rollback):
Removes the last committed Statepst(purge-states):
Purge old states. Keeps only the last
How to use Fim
You can download a Fim distribution
 Last release
Last releaseor build a version from the master (Details)
Fim prerequisites
Fim is written in Java. It requires Java 8
Works on Linux, Windows and Mac OS X
Tested on those three platforms
Fim Docker image
For Linux, if you do not have Java or not the correct version,
a docker image is available on Docker Hub


• Retrieve the fim-docker script 
curl https://raw.githubusercontent.com/evrignaud/fim/master/fim-docker -L -o fim-docker && chmod a+rx fim-docker• Launch Fim
The script retrieves the Fim Docker image, then starts.
It takes the same arguments as the fim command
./fim-docker -h• Update the image used
docker pull evrignaud/fimHands on

Ideas to try it yourself:
.fim content
The
.fimdirectory contains:A file with the repository settings:
settings.jsonA file for each state. It’s a JSON compressed file
The State
It contains a global hash which ensures the integrity.
Fim don’t allow to use a modified stateThe content of the State is standardized and can be used on the different supported OS
Changing The default hash mode
During the Fim repository initialization you can ask to not use some hash. This allows to have a repository where the commit will be faster, but there could be collisions:
• -f: Max. hash mode: fast. You can use after -f, -s or -n
• -s: Max. hash mode: super-fast. You can use after -s or -n
• -n: Max. hash mode: no-hash. You can use after -n
Example:
fim init -fAfter the status command works by default with the 'fast' level.
fim st # Runs using '-f'The hash algorithm used
The hash algorithm is SHA-512
SHA-512 is 2 * slower than MD5. It’s a cryptographic algorithm.
This decrease collisionsThe size of the key produced (512 Bit / 64 bytes) allows to minimize the collision risk on large files
The disk is slower than the hash algorithm
When the status is checked in full mode, the 3 hash are used which decrease the risk of collision
Performances

Fim can manage at least 1 million of files
Multi-thread hash in order to take advantage of the resources
In many cases, performance are conditioned by the speed of the disk
By default, the number of thread is dynamic and depends on the disk throughput
-toption to change the number of threads used (Details)
Hashing process
A Thread scans the workspace and fills the Queue of files to hash
Several thread hash each one a file:
— Calculation of the size and the location of the next block
— Block mapped into memory using a NIO FileChannel
— Hashing or not by the 3 hashers that produce the 3 hash
Using the MessageDigest
They receive the same blocks in order to reduce the I/O
and therefore read only once each block
More efficient than some C++ programs?
Purposely using btrfs RAID1 in degraded mode ?
https://www.spinics.net/lists/linux-btrfs/msg50990.html
For offline long term backups I also used to work with hashdeep to perform and store a hash of all the files and recently started playing with Fim which is similar but with a git backend for storing history. Don’t get fooled by fim being a java application.
It easily outperformed hashdeep on large datasets.
The different versions of Fim
> Fim changelog <
Articles that I have written to promote Fim on LinuxFr.org:
1.2.0 - Focus on performance with Fim 1.2.0
Support of repositories with at least 1 million of files1.1.0 - Fim 1.1.0
Hash algorithm rewrite to hash a block at the beginning,
one in the middle and one at the end1.0.2 - Fim release 1.0.2, that verifies the integrity of your file
First public version of Fim
They talked about it
Korben - Vérifier l’intégrité de très nombreux fichiers
Fim est un outil vraiment excellent qui permet de gérer l’intégrité de nombreux fichiers …01net.com - Pour Linux - Pour Windows
... permet de vérifier l’intégrité de tous vos fichiers après les avoir manipulés en lots …Pirate Informatique n°26 page 41 - Vérifiez l’intégrité de vos fichiers
Si vous avez un paquet de fichiers à transférer, vous aimeriez sans doute être absolument sûr que les données n’ont pas été endommagées …linux-btrfs - Purposely using btrfs RAID1 in degraded mode ? or here
... Don’t get fooled by fim being a java application. It easily outperformed hashdeep on large datasets.Stack Overflow - Signing every file created in a folder
OpenSource
Fim is published as OpenSource so that it benefits everyone.
That also makes it possible to profit from the ideas of each one.
Here are the ideas and merge request which have been submitted:
Do not hesitate to open issues with your ideas on GitHub
Fim alternatives
git-lfs - Git Large File Storage (LFS) replaces large files such as audio samples, videos, datasets, and graphics with text pointers inside Git
git-annex - Managing files with git, without checking the file contents into git
doc - Manage your files and documents
DIRT (DIRectory Tracker) - Another little Linux command line utility to track changed files in a directory tree.
MD5 Summer - Application for Windows 9x, NT, ME, 2000 and XP which generates and verifies md5 checksums
btrfs-scrub - Reads all data from the disk and verifies checksums
They don’t have super-fast mode for status or commit
Discovery of the GitHub project and the tools used


Asciidoctor - Ruby implementation of AsciiDoc to generate
the Fim documentation and this presentation slides
Questions
